This article is more than five years old.
Neuroscience—and science in general—is constantly evolving, so older articles may contain information or theories that have been reevaluated since their original publication date.
The National Institutes of Health on 30 September launched a public database to catalog a particularly important type of genomic data: so-called ‘structural variations’ — large deletions, duplications and rearrangements of DNA.
As more and more people have their genomes decoded, scientists are scrambling to find the best way to organize and analyze all of that DNA.
The National Institutes of Health on 30 September launched a public database to catalog a particularly important type of genomic data: so-called ‘structural variation’ — large deletions, duplications and rearrangements of DNA. A description of the new resource, dubbed dbVar, and how it will complement existing collections appears in the October issue of Nature Genetics.
The largest public database of genetic information was created in 1998, when researchers were most interested in single-base variations. These variations, or single-nucleotide polymorphisms (SNPs), have been linked to many diseases and are relatively simple to pick up using microarrays. Ever since, scientists have been dumping millions of SNPs into the database, called dbSNP.
But one of the most important genetic lessons learned in the past decade is that because SNPs frequently crop up in healthy people, they are not particularly helpful in predicting risk of a particular disease. In contrast, rare structural variants can be extremely informative.
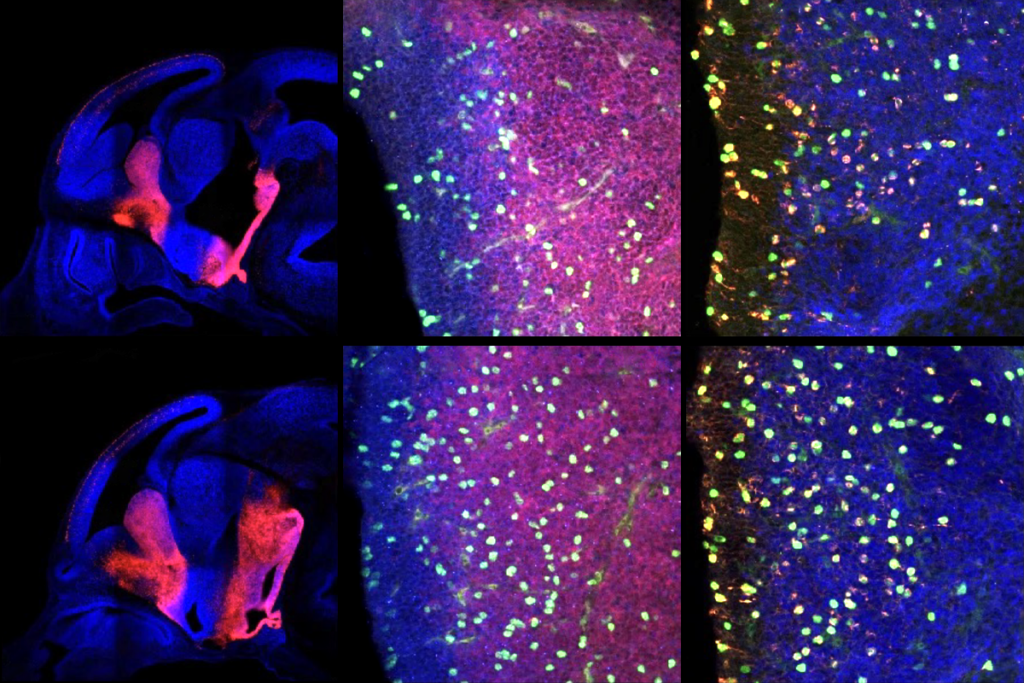
For example, loads of studies in the past few years have found a higher frequency of structural variations — particularly large deletions and duplications, or copy number variations — in people with autism, schizophrenia and other developmental disorders.
Although dbSNP holds some structural information, it wasn’t designed to include large structural variants (some of which span millions of letters of DNA). With dbVar, researchers may submit structural genomic data from people (healthy or not) or from any other organism, including monkeys, dogs, plants and insects.
Once the data are online, other researchers can mine the database for free, which will undoubtedly spur the discovery of interesting associations with various traits and diseases. I think the most useful feature of the database is how it displays this extremely complex set of data. For each study, the website allows you to see each variant in a ‘genome browser,’ a colorful graphical display of deletions and duplications on a particular chromosome — revealing hotbeds of mutation that might otherwise be difficult to spot.